Kubernetes API
Contenu du pack
Préambule
Ce Pack vise à superviser à la fois la couche d'infrastructure (noeuds) et les services d'un cluster Kubernetes (deployments, daemonsets, etc). Le Pack Kubernetes API offre plusieurs façons d'organiser la supervision du cluster. Il en existe principalement trois :
- Rassembler toutes les métriques sur un seul hôte Centreon avec un service par unité Kubernetes (i.e. deployments, daemonsets, etc) - voir utiliser un modèle d'hôte issu du connecteur,
- Rassembler toutes les métriques sur un seul hôte Centreon avec un service pour chaque instances de chaque unité Kubernetes - voir utiliser un modèle d'hôte issu du connecteur et utiliser un modèle de service issu du connecteur,
- Collecter les métriques d'infrastructure (noeuds maître et noeuds de travail) avec un hôte Centreon par noeud Kubernetes et conserver les métriques d'orchestration / d'application sur un hôte unique (en utilisant l'un des 2 scénarios précédents) - voir découverte d'hôte.
Modèles
Le connecteur de supervision Kubernetes API apporte 2 modèles d'hôte :
- Cloud-Kubernetes-Api-custom
- Cloud-Kubernetes-Kubectl-custom
- Cloud-Kubernetes-Node-Api-custom
- Cloud-Kubernetes-Node-Kubectl-custom
Le connecteur apporte les modèles de service suivants (classés selon le modèle d'hôte auquel ils sont rattachés) :
- Cloud-Kubernetes-Api-custom
- Cloud-Kubernetes-Kubectl-custom
- Cloud-Kubernetes-Node-Api-custom
- Cloud-Kubernetes-Node-Kubectl-custom
| Alias | Modèle de service | Description | Découverte |
|---|---|---|---|
| Cluster-Events | Cloud-Kubernetes-Cluster-Events-Api-custom | Contrôle le nombre d'événements survenant sur le cluster | |
| CronJob-Status | Cloud-Kubernetes-CronJob-Status-Api-custom | Contrôle le statut des CronJobs | X |
| Daemonset-Status | Cloud-Kubernetes-Daemonset-Status-Api-custom | Contrôle le statut des DaemonSets | X |
| Deployment-Status | Cloud-Kubernetes-Deployment-Status-Api-custom | Contrôle le statut des Deployments | X |
| Node-Status | Cloud-Kubernetes-Node-Status-Api-custom | Contrôle le statut des Nodes | |
| Node-Status | Cloud-Kubernetes-Node-Status-Name-Api-custom | Contrôle le statut d'un Node identifié par son nom (par exemple à l'issue de la règle de découverte associée) | X |
| Node-Usage | Cloud-Kubernetes-Node-Usage-Api-custom | Contrôle l'utilisation des noeuds | |
| Node-Usage | Cloud-Kubernetes-Node-Usage-Name-Api-custom | Contrôle l'utilisation d'un noeud identifié par son nom (par exemple à l'issue de la règle de découverte associée) | X |
| PersistentVolume-Status | Cloud-Kubernetes-PersistentVolume-Status-Api-custom | Contrôle le statut des PersistentVolumes | X |
| Pod-Status | Cloud-Kubernetes-Pod-Status-Api-custom | Contrôle le statut des pods et des containers | X |
| ReplicaSet-Status | Cloud-Kubernetes-ReplicaSet-Status-Api-custom | Contrôle le statut des ReplicaSets | X |
| ReplicationController-Status | Cloud-Kubernetes-ReplicationController-Status-Api-custom | Contrôle le statut des ReplicationControllers | X |
| StatefulSet-Status | Cloud-Kubernetes-StatefulSet-Status-Api-custom | Contrôle le statut des StatefulSets | X |
Les services listés ci-dessus sont créés automatiquement lorsque le modèle d'hôte Cloud-Kubernetes-Api-custom est utilisé.
Si la case Découverte est cochée, cela signifie qu'une règle de découverte de service existe pour ce service.
| Alias | Modèle de service | Description | Découverte |
|---|---|---|---|
| Cluster-Events | Cloud-Kubernetes-Cluster-Events-Api-custom | Contrôle le nombre d'événements survenant sur le cluster | |
| CronJob-Status | Cloud-Kubernetes-CronJob-Status-Api-custom | Contrôle le statut des CronJobs | X |
| Daemonset-Status | Cloud-Kubernetes-Daemonset-Status-Api-custom | Contrôle le statut des DaemonSets | X |
| Deployment-Status | Cloud-Kubernetes-Deployment-Status-Api-custom | Contrôle le statut des Deployments | X |
| Node-Status | Cloud-Kubernetes-Node-Status-Api-custom | Contrôle le statut des Nodes | |
| Node-Status | Cloud-Kubernetes-Node-Status-Name-Api-custom | Contrôle le statut d'un Node identifié par son nom (par exemple à l'issue de la règle de découverte associée) | X |
| Node-Usage | Cloud-Kubernetes-Node-Usage-Api-custom | Contrôle l'utilisation des noeuds | |
| Node-Usage | Cloud-Kubernetes-Node-Usage-Name-Api-custom | Contrôle l'utilisation d'un noeud identifié par son nom (par exemple à l'issue de la règle de découverte associée) | X |
| PersistentVolume-Status | Cloud-Kubernetes-PersistentVolume-Status-Api-custom | Contrôle le statut des PersistentVolumes | X |
| Pod-Status | Cloud-Kubernetes-Pod-Status-Api-custom | Contrôle le statut des pods et des containers | X |
| ReplicaSet-Status | Cloud-Kubernetes-ReplicaSet-Status-Api-custom | Contrôle le statut des ReplicaSets | X |
| ReplicationController-Status | Cloud-Kubernetes-ReplicationController-Status-Api-custom | Contrôle le statut des ReplicationControllers | X |
| StatefulSet-Status | Cloud-Kubernetes-StatefulSet-Status-Api-custom | Contrôle le statut des StatefulSets | X |
Les services listés ci-dessus sont créés automatiquement lorsque le modèle d'hôte Cloud-Kubernetes-Kubectl-custom est utilisé.
Si la case Découverte est cochée, cela signifie qu'une règle de découverte de service existe pour ce service.
| Alias | Modèle de service | Description | Découverte |
|---|---|---|---|
| Node-Status | Cloud-Kubernetes-Node-Status-Api-custom | Contrôle le statut des Nodes | |
| Node-Status | Cloud-Kubernetes-Node-Status-Name-Api-custom | Contrôle le statut d'un Node identifié par son nom (par exemple à l'issue de la règle de découverte associée) | X |
| Node-Usage | Cloud-Kubernetes-Node-Usage-Api-custom | Contrôle l'utilisation des noeuds | |
| Node-Usage | Cloud-Kubernetes-Node-Usage-Name-Api-custom | Contrôle l'utilisation d'un noeud identifié par son nom (par exemple à l'issue de la règle de découverte associée) | X |
Les services listés ci-dessus sont créés automatiquement lorsque le modèle d'hôte Cloud-Kubernetes-Node-Api-custom est utilisé.
Si la case Découverte est cochée, cela signifie qu'une règle de découverte de service existe pour ce service.
| Alias | Modèle de service | Description | Découverte |
|---|---|---|---|
| Node-Status | Cloud-Kubernetes-Node-Status-Api-custom | Contrôle le statut des Nodes | |
| Node-Status | Cloud-Kubernetes-Node-Status-Name-Api-custom | Contrôle le statut d'un Node identifié par son nom (par exemple à l'issue de la règle de découverte associée) | X |
| Node-Usage | Cloud-Kubernetes-Node-Usage-Api-custom | Contrôle l'utilisation des noeuds | |
| Node-Usage | Cloud-Kubernetes-Node-Usage-Name-Api-custom | Contrôle l'utilisation d'un noeud identifié par son nom (par exemple à l'issue de la règle de découverte associée) | X |
Les services listés ci-dessus sont créés automatiquement lorsque le modèle d'hôte Cloud-Kubernetes-Node-Kubectl-custom est utilisé.
Si la case Découverte est cochée, cela signifie qu'une règle de découverte de service existe pour ce service.
Règles de découverte
Découverte d'hôtes
| Nom de la règle | Description |
|---|---|
| Kubernetes Nodes (RestAPI) | Découvrez les noeuds Kubernetes en interrogeant l'API Rest Kubernetes |
| Kubernetes Nodes (Kubectl) | Découvrez les noeuds Kubernetes en interrogeant le cluster Kubernetes avec kubectl |
Rendez-vous sur la documentation dédiée pour en savoir plus sur la découverte automatique d'hôtes.
Découverte de services
| Nom de la règle | Description |
|---|---|
| Cloud-Kubernetes-Api-CronJobs-Status | Découvrez les CronJobs Kubernetes pour superviser leur statut |
| Cloud-Kubernetes-Api-Daemonsets-Status | Découvrez les DaemonSets Kubernetes pour superviser leur statut |
| Cloud-Kubernetes-Api-Deployments-Status | Découvrez les Deployments Kubernetes pour superviser leur statut |
| Cloud-Kubernetes-Api-Nodes-Status | Découvrez les Nodes Kubernetes pour superviser leur statut |
| Cloud-Kubernetes-Api-Nodes-Usage | Découvrez les Nodes Kubernetes pour superviser leur utilisation |
| Cloud-Kubernetes-Api-PersistentVolumes-Status | Découvrez les PersistentVolumes Kubernetes pour superviser leur statut |
| Cloud-Kubernetes-Api-Pods-Status | Découvrez les Pods Kubernetes pour superviser leur statut |
| Cloud-Kubernetes-Api-ReplicaSets-Status | Découvrez les ReplicaSets Kubernetes pour superviser leur statut |
| Cloud-Kubernetes-Api-ReplicationControllers-Status | Découvrez les ReplicationControllers Kubernetes pour superviser leur statut |
| Cloud-Kubernetes-Api-StatefulSets-Status | Découvrez les StatefulSets Kubernetes pour superviser leur statut |
Rendez-vous sur la documentation dédiée pour en savoir plus sur la découverte automatique de services et sa planification.
Métriques & statuts collectés
Voici le tableau des services pour ce connecteur, détaillant les métriques rattachées à chaque service.
- Cluster-Events
- CronJob-Status
- Daemonset-Status
- Deployment-Status
- Node-Status*
- Node-Usage*
- PersistentVolume-Status
- Pod-Status
- ReplicaSet-Status
- ReplicationController-Status
- StatefulSet-Status
| Métrique | Unité |
|---|---|
| events.type.warning.count | count |
| events.type.normal.count | count |
| events#status | N/A |
| Métrique | Unité |
|---|---|
| cronjobs#cronjob.jobs.active.count | count |
| Métrique | Unité |
|---|---|
| daemonsets#daemonset.pods.misscheduled.count | count |
| Métrique | Unité |
|---|---|
| deployments#deployment.replicas.uptodate.count | count |
| Métrique | Unité |
|---|---|
| nodes~conditions#status | N/A |
Concerne les modèles de service suivants : Node-Status, Node-Status
| Métrique | Unité |
|---|---|
| nodes#cpu.requests.percentage | % |
| nodes#cpu.limits.percentage | % |
| nodes#memory.requests.percentage | % |
| nodes#memory.limits.percentage | % |
| nodes#pods.allocation.percentage | % |
Concerne les modèles de service suivants : Node-Usage, Node-Usage
| Métrique | Unité |
|---|---|
| pvs#status | N/A |
| Métrique | Unité |
|---|---|
| pods~containers.ready.count | count |
| pods~pod-status | N/A |
| pods~restarts.total.count | count |
| pods~containers#container-status | N/A |
| pods~containers#containers.restarts.count | count |
| Métrique | Unité |
|---|---|
| replicasets#replicaset.replicas.ready.count | count |
| Métrique | Unité |
|---|---|
| rcs#replicationcontroller.replicas.ready.count | count |
| Métrique | Unité |
|---|---|
| statefulsets#statefulset.replicas.ready.count | count |
Informations complémentaires sur les métriques et services
Voici le tableau des services pour ce connecteur, détaillant les métriques rattachées à chaque service.
- Cluster-Events
- CronJob-Status
- Daemonset-Status
- Deployment-Status
- Node-Status*
- Node-Usage*
- PersistentVolume-Status
- Pod-Status
- ReplicaSet-Status
- ReplicationController-Status
- StatefulSet-Status
Cet indicateur permet de superviser le nombre d'événements se produisant sur
le cluster. Si la commande kubectl get events a pour sortie :
NAMESPACE LAST SEEN TYPE REASON OBJECT MESSAGE
graphite 26m Warning Unhealthy pod/graphite-0 Liveness probe failed: Get "http://10.244.2.10:8080/": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
Alors la sortie résultante dans Centreon pourrait ressembler à :
Event 'Warning' for object 'Pod/graphite-0' with message 'Liveness probe failed: Get "http://10.244.2.10:8080/": context deadline exceeded (Client.Timeout exceeded while awaiting headers)', Count: 1, First seen: 26m 21s ago (2021-03-11T12:26:23Z), Last seen: 26m 21s ago (2021-03-11T12:26:23Z)
Cet indicateur permet de vérifier que les CronJobs sont exécutés comme ils
le devraient. Si la commande kubectl get cronjobs a pour sortie :
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 1 6s 2d1h
Alors la sortie résultante dans Centreon pourrait ressembler à :
CronJob 'hello' Jobs Active: 1, Last schedule time: 6s ago (2021-03-11T12:31:00Z)
Si le service collecte des métriques de plusieurs CronJobs (selon le scénario choisi), le nom du CronJob sera ajouté au nom de la métrique :
| Métrique |
|---|
hello#cronjob.jobs.active.count |
Cet indicateur garantira que les DaemonSets sont dans des limites définies
en regardant le nombre de Pods disponibles et/ou à jour par rapport au
nombre souhaité. Si la commande kubectl get daemonsets a pour sortie :
NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-system kube-flannel-ds-amd64 3 3 3 3 3 beta.kubernetes.io/arch=amd64 624d
kube-system kube-proxy 3 3 3 3 3 kubernetes.io/os=linux 624d
Alors la sortie résultante dans Centreon pourrait ressembler à :
Daemonset 'kube-flannel-ds-amd64' Pods Desired: 3, Current: 3, Available: 3, Up-to-date: 3, Ready: 3, Misscheduled: 0
Daemonset 'kube-proxy' Pods Desired: 3, Current: 3, Available: 3, Up-to-date: 3, Ready: 3, Misscheduled: 0
Si le service collecte des métriques de plusieurs DaemonSets (selon le scénario choisi), le nom du DaemonSet sera ajouté au nom de la métrique :
| Métrique |
|---|
kube-proxy#daemonset.pods.desired.count |
Cet indicateur garantira que les Deployments sont dans des limites définies
en examinant le nombre de répliques disponibles et/ou à jour par rapport au
nombre souhaité. Si la commande kubectl get deployments a pour sortie :
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
kube-system coredns 2/2 2 2 624d
kube-system tiller-deploy 1/1 1 1 624d
kubernetes-dashboard dashboard-metrics-scraper 1/1 1 1 37d
kubernetes-dashboard kubernetes-dashboard 1/1 1 1 37d
Alors la sortie résultante dans Centreon pourrait ressembler à :
Deployment 'coredns' Replicas Desired: 2, Current: 2, Available: 2, Ready: 2, Up-to-date: 2
Deployment 'tiller-deploy' Replicas Desired: 1, Current: 1, Available: 1, Ready: 1, Up-to-date: 1
Deployment 'dashboard-metrics-scraper' Replicas Desired: 1, Current: 1, Available: 1, Ready: 1, Up-to-date: 1
Deployment 'kubernetes-dashboard' Replicas Desired: 1, Current: 1, Available: 1, Ready: 1, Up-to-date: 1
Si le service collecte des métriques de plusieurs Deployments (selon le scénario choisi), le nom du Deployment sera ajouté au nom de la métrique :
| Métrique |
|---|
tiller-deploy#deployment.replicas.desired.count |
Cet indicateur garantira que les noeuds fonctionnent bien en regardant
les statuts des conditions. Si la commande kubectl describe nodes a pour sortie :
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
MemoryPressure False Thu, 11 Mar 2021 14:20:25 +0100 Tue, 26 Jan 2021 09:38:11 +0100 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Thu, 11 Mar 2021 14:20:25 +0100 Wed, 17 Feb 2021 09:37:40 +0100 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Thu, 11 Mar 2021 14:20:25 +0100 Tue, 26 Jan 2021 09:38:11 +0100 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Thu, 11 Mar 2021 14:20:25 +0100 Tue, 26 Jan 2021 17:26:36 +0100 KubeletReady kubelet is posting ready status
Alors la sortie résultante dans Centreon pourrait ressembler à :
Condition 'DiskPressure' Status is 'False', Reason: 'KubeletHasNoDiskPressure', Message: 'kubelet has no disk pressure'
Condition 'MemoryPressure' Status is 'False', Reason: 'KubeletHasSufficientMemory', Message: 'kubelet has sufficient memory available'
Condition 'PIDPressure' Status is 'False', Reason: 'KubeletHasSufficientPID', Message: 'kubelet has sufficient PID available'
Condition 'Ready' Status is 'True', Reason: 'KubeletReady', Message: 'kubelet is posting ready status'
Cet indicateur rassemblera des métriques sur l'utilisation des noeuds comme l'allocation des Pods, les demandes de CPU et de mémoire faites par ces Pods, et les limites de CPU et de mémoire autorisées pour ces mêmes Pods.
En utilisant l'outil de ligne de commande Kubernetes, cela pourrait ressembler à ce qui suit :
-
Capacité des noeuds :
kubectl get nodes -o=custom-columns="NODE:.metadata.name,PODS ALLOCATABLE:.status.allocatable.pods,CPU ALLOCATABLE:.status.allocatable.cpu,MEMORY ALLOCATABLE:.status.allocatable.memory"
NODE PODS ALLOCATABLE CPU ALLOCATABLE MEMORY ALLOCATABLE
master-node 110 2 3778172Ki
worker-node 110 2 3778184Ki -
Pods en cours d'exécution :
kubectl get pods -o=custom-columns="NODE:.spec.nodeName,POD:.metadata.name,CPU REQUESTS:.spec.containers[*].resources.requests.cpu,CPU LIMITS:.spec.containers[*].resources.limits.cpu,MEMORY REQUESTS:.spec.containers[*].resources.requests.memory,MEMORY LIMITS:.spec.containers[*].resources.limits.memory"
NODE POD CPU REQUESTS CPU LIMITS MEMORY REQUESTS MEMORY LIMITS
worker-node coredns-74ff55c5b-g4hmt 100m <none> 70Mi 170Mi
master-node etcd-master-node 100m <none> 100Mi <none>
master-node kube-apiserver-master-node 250m <none> <none> <none>
master-node kube-controller-manager-master-node 200m <none> <none> <none>
master-node kube-flannel-ds-amd64-fk59g 100m 100m 50Mi 50Mi
worker-node kube-flannel-ds-amd64-jwzms 100m 100m 50Mi 50Mi
master-node kube-proxy-kkwmb <none> <none> <none> <none>
worker-node kube-proxy-vprs8 <none> <none> <none> <none>
master-node kube-scheduler-master-node 100m <none> <none> <none>
master-node kubernetes-dashboard-7d75c474bb-7zc5j <none> <none> <none> <none>
Depuis le tableau de bord Kubernetes, les métriques se trouvent dans le
menu Cluster > Nodes:
-
Liste depuis
Cluser > Nodes: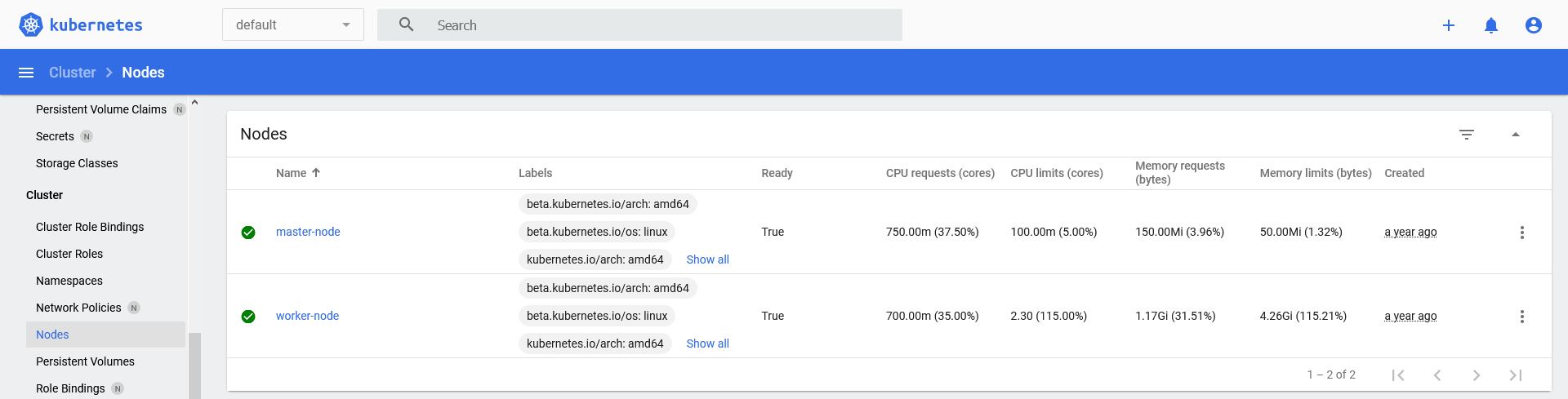
-
Détail de l'allocation pour un noeud :
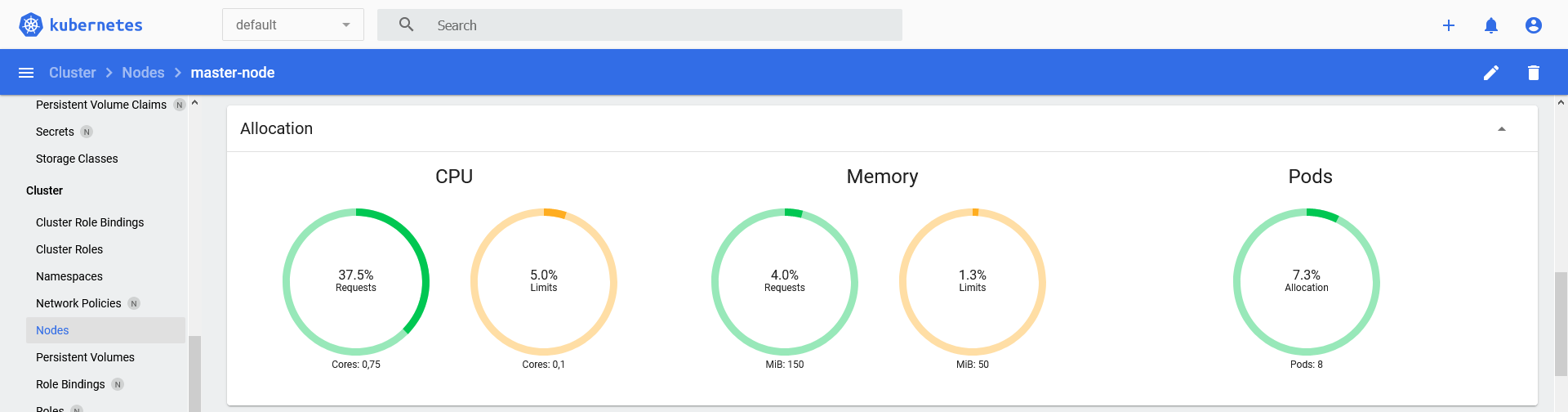
La sortie résultante dans Centreon pourrait ressembler à :
Node 'master-node' CPU requests: 37.50% (0.75/2), CPU limits: 5.00% (0.1/2), Memory requests: 3.96% (150.00MB/3.70GB), Memory limits: 1.32% (50.00MB/3.70GB), Pods allocation: 7.27% (8/110)
Node 'worker-node' CPU requests: 35.00% (0.7/2), CPU limits: 115.00% (2.3/2), Memory requests: 31.51% (1.17GB/3.70GB), Memory limits: 115.21% (4.26GB/3.70GB), Pods allocation: 9.09% (10/110)
Si le service collecte des métriques de plusieurs Nodes (selon le scénario choisi), le nom du Node sera ajouté au nom de la métrique:
| Métrique |
|---|
worker-node#pods.allocation.percentage |
Cet indicateur garantira que les PersistentVolumes fonctionnent correctement
en regardant la phase dans laquelle ils se trouvent. Si la commande
kubectl get pv a pour sortie :
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv-nfs-kubestorage-001 5Gi RWO Retain Available 630d
pv-nfs-kubestorage-002 5Gi RWO Retain Bound tick/data-influxdb 630d
pv-nfs-kubestorage-003 5Gi RWO Retain Released graphite/graphite-pvc 630d
Alors la sortie résultante dans Centreon pourrait ressembler à :
Persistent Volume 'pv-nfs-kubestorage-001' Phase is 'Available'
Persistent Volume 'pv-nfs-kubestorage-002' Phase is 'Bound'
Persistent Volume 'pv-nfs-kubestorage-003' Phase is 'Released'
Cet indicateur garantira que les Pods et leurs conteneurs sont dans des
limites définies en regardant le nombre de conteneurs prêts par rapport au
nombre souhaité. Si la commande kubectl get pods a pour sortie :
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system kube-proxy-65zhn 1/1 Running 0 37d
kube-system kube-proxy-kkwmb 1/1 Running 0 37d
kube-system kube-proxy-vprs8 1/1 Running 0 37d
kube-system tiller-deploy-7bf78cdbf7-z5n24 1/1 Running 5 550d
kubernetes-dashboard dashboard-metrics-scraper-79c5968bdc-vncxc 1/1 Running 0 37d
kubernetes-dashboard kubernetes-dashboard-7448ffc97b-42rps 1/1 Running 0 37d
Alors la sortie résultante dans Centreon pourrait ressembler à :
Checking pod 'kube-proxy-65zhn'
Containers Ready: 1/1 (100.00%), Status is 'Running', Restarts: 0
Container 'kube-proxy' Status is 'running', State is 'ready', Restarts: 0
Checking pod 'kube-proxy-kkwmb'
Containers Ready: 1/1 (100.00%), Status is 'Running', Restarts: 0
Container 'kube-proxy' Status is 'running', State is 'ready', Restarts: 0
Checking pod 'kube-proxy-vprs8'
Containers Ready: 1/1 (100.00%), Status is 'Running', Restarts: 0
Container 'kube-proxy' Status is 'running', State is 'ready', Restarts: 0
Checking pod 'tiller-deploy-7bf78cdbf7-z5n24'
Containers Ready: 1/1 (100.00%), Status is 'Running', Restarts: 5
Container 'tiller' Status is 'running', State is 'ready', Restarts: 5
Checking pod 'dashboard-metrics-scraper-79c5968bdc-vncxc'
Containers Ready: 1/1 (100.00%), Status is 'Running', Restarts: 0
Container 'dashboard-metrics-scraper' Status is 'running', State is 'ready', Restarts: 0
Checking pod 'kubernetes-dashboard-7448ffc97b-42rps'
Containers Ready: 1/1 (100.00%), Status is 'Running', Restarts: 0
Container 'kubernetes-dashboard' Status is 'running', State is 'ready', Restarts: 0
Si le service collecte des métriques de plusieurs Pods (en fonction du scénario choisi), le nom du Pod et le nom du conteneur seront ajoutés au nom de la métrique :
| Métrique |
|---|
coredns-74ff55c5b-g4hmt#containers.ready.count |
coredns-74ff55c5b-g4hmt#restarts.total.count |
coredns-74ff55c5b-g4hmt_coredns#containers.restarts.count |
Cet indicateur garantira que les ReplicaSets sont dans les limites définies
en regardant le nombre de répliques prêtes par rapport au nombre souhaité,
ce en se basant sur les informations disponibles en sortie de la commande kubectl get replicasets :
NAMESPACE NAME DESIRED CURRENT READY AGE
kube-system coredns-74ff55c5b 2 2 2 44d
kube-system tiller-deploy-7bf78cdbf7 1 1 1 630d
kubernetes-dashboard dashboard-metrics-scraper-79c5968bdc 1 1 1 44d
kubernetes-dashboard kubernetes-dashboard-7448ffc97b 1 1 1 44d
La sortie résultante dans Centreon pourrait ressembler à :
ReplicaSet 'coredns-74ff55c5b' Replicas Desired: 2, Current: 2, Ready: 2
ReplicaSet 'tiller-deploy-7bf78cdbf7' Replicas Desired: 1, Current: 1, Ready: 1
ReplicaSet 'dashboard-metrics-scraper-79c5968bdc' Replicas Desired: 1, Current: 1, Ready: 1
ReplicaSet 'kubernetes-dashboard-7448ffc97b' Replicas Desired: 1, Current: 1, Ready: 1
Si le service collecte des métriques de plusieurs ReplicaSets (selon le scénario choisi), le nom du ReplicaSet sera ajouté au nom de la métrique :
| Métrique |
|---|
tiller-deploy-7bf78cdbf7#replicaset.replicas.desired.count |
Cet indicateur garantira que les ReplicationControllers sont dans les limites
définies en regardant le nombre de répliques prêtes par rapport au nombre
souhaité. Si la commande kubectl get rc a pour sortie :
NAMESPACE NAME DESIRED CURRENT READY AGE
elk nginx 3 3 3 2d19h
Alors la sortie résultante dans Centreon pourrait ressembler à :
ReplicationController 'nginx' Replicas Desired: 3, Current: 3, Ready: 3
Si le service collecte des métriques de plusieurs ReplicationControllers (selon le scénario choisi), le nom du ReplicationController sera ajouté au nom de la métrique :
| Métrique |
|---|
nginx#replicationcontroller.replicas.desired.count |
Cet indicateur garantira que les StatefulSets sont dans des limites définies
en regardant le nombre de répliques prêtes / à jour par rapport au nombre
souhaité. Si la commande kubectl get statefulsets a pour sortie :
NAMESPACE NAME READY AGE
elk elasticsearch-master 2/2 44d
graphite graphite 1/1 3d
prometheus prometheus-prometheus-operator-prometheus 1/1 619d
Alors la sortie résultante dans Centreon pourrait ressembler à :
StatefulSet 'elasticsearch-master' Replicas Desired: 2, Current: 2, Up-to-date: 2, Ready: 2
StatefulSet 'graphite' Replicas Desired: 1, Current: 1, Up-to-date: 1, Ready: 1
StatefulSet 'prometheus-prometheus-operator-prometheus' Replicas Desired: 1, Current: 1, Up-to-date: 1, Ready: 1
Si le service collecte des métriques de plusieurs StatefulSets (selon le scénario choisi), le nom du StatefulSet sera ajouté au nom de la métrique :
| Métrique |
|---|
graphite#statefulset.replicas.desired.count |
Prérequis
Comme mentionné dans l'introduction, deux modes de communication sont disponibles:
- l'API Rest exposée par le cluster Kubernetes,
- l'outil CLI kubectl pour communiquer avec le control plane du cluster.
Pour de meilleures performances, nous vous recommandons d'utiliser l'API Rest.
Créer un compte de service
Les deux versions doivent utiliser un compte de service avec des droits suffisants pour accéder à l'API Kubernetes.
Créez un compte de service dédié centreon-service-account dans l'espace de
noms kube-system pour accéder à l'API:
kubectl create serviceaccount centreon-service-account --namespace kube-system
Créez un rôle de cluster api-access avec les privilèges nécessaires pour le
plugin et liez-le au compte de service nouvellement créé :
cat <<EOF | kubectl create -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: api-access
rules:
- apiGroups:
- ""
- apps
- batch
resources:
- cronjobs
- daemonsets
- deployments
- events
- namespaces
- nodes
- persistentvolumes
- pods
- replicasets
- replicationcontrollers
- statefulsets
verbs:
- get
- list
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: api-access
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: api-access
subjects:
- kind: ServiceAccount
name: centreon-service-account
namespace: kube-system
EOF
Se référer à la documentation officielle pour la création de compte de service ou pour des informations sur le concept de secret.
Kubectl version 1.24 et supérieures
Dans les versions antérieures à Kubernetes 1.24, chaque compte de service créé obtenait automatiquement un jeton secret de type JWT (JSON Web Token) monté dans les pods associés. À partir de Kubernetes 1.24 : Ces jetons automatiques ne sont plus générés par défaut Pour créer manuellement le token référez-vous à la documentation officielle de kubernetes Manually create a long-lived API token for a ServiceAccount.
Utilisation de l'API Rest
Si vous avez choisi de communiquer avec l'API Rest de votre plateforme Kubernetes, les conditions préalables suivantes doivent être remplies :
- Exposez l'API avec TLS,
- Récupérez le jeton du compte de service.
Exposez l'API
Comme l'API utilise HTTPS, vous aurez besoin d'un certificat.
Vous pouvez créer un couple clé / certificat signé automatiquement avec la commande suivante :
openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /etc/ssl/private/kubernetesapi.key -out /etc/ssl/certs/kubernetesapi.crt
Puis chargez-le en tant que api-certificate dans le cluster, à partir du
noeud maître :
kubectl create secret tls api-certificate --key /etc/ssl/private/kubernetesapi.key --cert /etc/ssl/certs/kubernetesapi.crt
L'entrée peut maintenant être créée :
cat <<EOF | kubectl create -f -
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: kubernetesapi-ingress
namespace: default
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/backend-protocol: "HTTPS"
spec:
tls:
- hosts:
- kubernetesapi.local.domain
secretName: api-certificate
rules:
- host: kubernetesapi.local.domain
http:
paths:
- path: /
pathType: ImplementationSpecific
backend:
service:
name: kubernetes
port:
number: 443
EOF
Adaptez les entrées host à vos besoins.
Se référer à la documentation officielle pour la gestion des ingress.
Récupérer le jeton du compte de service
Récupérez le secret du compte de service précédemment créé :
kubectl get serviceaccount centreon-service-account --namespace kube-system --output jsonpath='{.secrets[].name}'
Récupérez ensuite le jeton du secret du compte de service :
kubectl get secrets centreon-service-account-token-xqw7m --namespace kube-system --output jsonpath='{.data.token}' | base64 --decode
Ce jeton sera utilisé ultérieurement pour la configuration de l'hôte Centreon.
Utilisation de kubectl
Si vous avez choisi de communiquer avec le control plane du cluster avec kubectl, les conditions préalables suivantes doivent être remplies:
- Installez l'outil kubectl,
- Créez une configuration kubectl.
Ces actions sont nécessaires sur tous les Pollers qui effectueront la supervision de Kubernetes.
Installer kubectl
Téléchargez la dernière version avec la commande suivante :
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
Assurez-vous de télécharger une version avec une différence d'au maximum une version mineure de votre cluster. Pour télécharger une version spécifique, changez le contenu de la commande curl incluse dans la commande ci-dessus, permettant de récupérer le numéro de version. Par exemple pour télécharger la version
1.20.0voici la commande :curl -LO "https://dl.k8s.io/release/v1.20.0/bin/linux/amd64/kubectl"
Installez l'outil dans le répertoire des binaires :
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
Référez vous à la documentation officielle pour plus de détails.
Créer une configuration kubectl
Pour accéder au cluster, kubectl a besoin d'un fichier de configuration contenant toutes les informations nécessaires.
Voici un exemple de création de fichier de configuration basé sur un compte de service (créé au chapitre précédent).
Vous devrez remplir les informations suivantes et exécuter les commandes sur le noeud maître:
ip=<master node ip>
port=<api port>
account=centreon-service-account
namespace=kube-system
clustername=my-kube-cluster
context=my-kube-cluster
secret=$(kubectl get serviceaccount $account --namespace $namespace --output jsonpath='{.secrets[].name}')
ca=$(kubectl get secret $secret --namespace $namespace --output jsonpath='{.data.ca\.crt}')
token=$(kubectl get secret $secret --namespace $namespace --output jsonpath='{.data.token}' | base64 --decode)
Le nom du compte et l'espace de noms doivent correspondre au compte créé précédemment. Toutes les autres informations doivent être adaptées.
Exécutez ensuite cette commande pour générer le fichier de configuration :
cat <<EOF >> config
apiVersion: v1
kind: Config
clusters:
- name: ${clustername}
cluster:
certificate-authority-data: ${ca}
server: https://${ip}:${port}
contexts:
- name: ${context}
context:
cluster: ${clustername}
namespace: ${namespace}
user: ${account}
current-context: ${context}
users:
- name: ${account}
user: ${token}
EOF
Cela créera un fichier config. Ce fichier doit être copié dans le répertoire
racine de l'utilisateur de l'Engine du Poller, généralement dans un répertoire
.kube (c'est-à-dire /var/lib/centreon-engine/.kube/config).
Ce chemin sera utilisé ultérieurement dans la configuration de l'hôte Centreon.
Vous devez également copier la configuration dans le répertoire de l'utilisateur Gorgone si vous utilisez Host Discovery.
Référez vous à la documentation officielle pour plus de détails.
Installer le connecteur de supervision
Pack
La procédure d'installation des connecteurs de supervision diffère légèrement suivant que votre licence est offline ou online.
- Si la plateforme est configurée avec une licence online, l'installation d'un paquet n'est pas requise pour voir apparaître le connecteur dans le menu Configuration > Connecteurs > Connecteurs de supervision. Au contraire, si la plateforme utilise une licence offline, installez le paquet sur le serveur central via la commande correspondant au gestionnaire de paquets associé à sa distribution :
- Alma / RHEL / Oracle Linux 8
- Alma / RHEL / Oracle Linux 9
- Debian 11 & 12
- CentOS 7
dnf install centreon-pack-cloud-kubernetes-api
dnf install centreon-pack-cloud-kubernetes-api
apt install centreon-pack-cloud-kubernetes-api
yum install centreon-pack-cloud-kubernetes-api
- Quel que soit le type de la licence (online ou offline), installez le connecteur Kubernetes API depuis l'interface web et le menu Configuration > Connecteurs > Connecteurs de supervision.
Plugin
À partir de Centreon 22.04, il est possible de demander le déploiement automatique du plugin lors de l'utilisation d'un connecteur. Si cette fonctionnalité est activée, et que vous ne souhaitez pas découvrir des éléments pour la première fois, alors cette étape n'est pas requise.
Plus d'informations dans la section Installer le plugin.
Utilisez les commandes ci-dessous en fonction du gestionnaire de paquets de votre système d'exploitation :
- Alma / RHEL / Oracle Linux 8
- Alma / RHEL / Oracle Linux 9
- Debian 11 & 12
- CentOS 7
dnf install centreon-plugin-Cloud-Kubernetes-Api
dnf install centreon-plugin-Cloud-Kubernetes-Api
apt install centreon-plugin-cloud-kubernetes-api
yum install centreon-plugin-Cloud-Kubernetes-Api
Utiliser le connecteur de supervision
Utiliser un modèle d'hôte issu du connecteur
- Cloud-Kubernetes-Api-custom
- Cloud-Kubernetes-Kubectl-custom
- Cloud-Kubernetes-Node-Api-custom
- Cloud-Kubernetes-Node-Kubectl-custom
- Ajoutez un hôte à Centreon depuis la page Configuration > Hôtes.
- Complétez les champs Nom, Alias & IP Address/DNS correspondant à votre ressource.
- Appliquez le modèle d'hôte Cloud-Kubernetes-Api-custom. Une liste de macros apparaît. Les macros vous permettent de définir comment le connecteur se connectera à la ressource, ainsi que de personnaliser le comportement du connecteur.
- Renseignez les macros désirées. Attention, certaines macros sont obligatoires, notamment la macro permettant de définir le custom mode, c'est-à-dire la méthode de connexion à la ressource.
| Macro | Description | Valeur par défaut | Obligatoire |
|---|---|---|---|
| KUBERNETESAPIHOSTNAME | Hostname or address of the Kubernetes API service | X | |
| KUBERNETESAPITOKEN | Token retrieved from service account | X | |
| KUBERNETESAPIPROTO | Specify https if needed | https | |
| KUBERNETESAPIPORT | API port | 443 | |
| KUBERNETESAPICUSTOMMODE | When a plugin offers several ways (CLI, library, etc.) to get information the desired one must be defined with this option | api | |
| KUBERNETESAPINAMESPACE | Set namespace to get informations | ||
| KUBERNETESNODENAME | Filter StatefulSet name (can be a regexp) | ||
| PROXYURL | Proxy URL if any | ||
| TIMEOUT | Set timeout in seconds | 10 | |
| EXTRAOPTIONS | Any extra option you may want to add to every command (a --verbose flag for example). Toutes les options sont listées ici. |
- Déployez la configuration. L'hôte apparaît dans la liste des hôtes supervisés, et dans la page Statut des ressources. La commande envoyée par le connecteur est indiquée dans le panneau de détails de l'hôte : celle-ci montre les valeurs des macros.
Pour la découverte d'hôte : définissez le jeton récupéré plus tôt à partir du compte de service,
- Ajoutez un hôte à Centreon depuis la page Configuration > Hôtes.
- Complétez les champs Nom, Alias & IP Address/DNS correspondant à votre ressource.
- Appliquez le modèle d'hôte Cloud-Kubernetes-Kubectl-custom. Une liste de macros apparaît. Les macros vous permettent de définir comment le connecteur se connectera à la ressource, ainsi que de personnaliser le comportement du connecteur.
- Renseignez les macros désirées. Attention, certaines macros sont obligatoires, notamment la macro permettant de définir le custom mode, c'est-à-dire la méthode de connexion à la ressource.
| Macro | Description | Valeur par défaut | Obligatoire |
|---|---|---|---|
| KUBECTLCONFIGFILE | Kubernetes configuration file path. | ~/.kube/config | X |
| KUBERNETESAPICUSTOMMODE | When a plugin offers several ways (CLI, library, etc.) to get information the desired one must be defined with this option | kubectl | |
| KUBERNETESNODENAME | Filter StatefulSet name (can be a regexp) | ||
| PROXYURL | Proxy URL if any | ||
| TIMEOUT | Set timeout in seconds | 10 | |
| EXTRAOPTIONS | Any extra option you may want to add to every command (a --verbose flag for example). Toutes les options sont listées ici. |
- Déployez la configuration. L'hôte apparaît dans la liste des hôtes supervisés, et dans la page Statut des ressources. La commande envoyée par le connecteur est indiquée dans le panneau de détails de l'hôte : celle-ci montre les valeurs des macros.
Pour la découverte d'hôte : définissez le chemin vers le fichier de configuration créé (utilisez le chemin relatif pour le faire fonctionner à la fois pour la découverte et la supervision, c'est-à-dire
~/.kube/config).
- Ajoutez un hôte à Centreon depuis la page Configuration > Hôtes.
- Complétez les champs Nom, Alias & IP Address/DNS correspondant à votre ressource.
- Appliquez le modèle d'hôte Cloud-Kubernetes-Node-Api-custom. Une liste de macros apparaît. Les macros vous permettent de définir comment le connecteur se connectera à la ressource, ainsi que de personnaliser le comportement du connecteur.
- Renseignez les macros désirées. Attention, certaines macros sont obligatoires, notamment la macro permettant de définir le custom mode, c'est-à-dire la méthode de connexion à la ressource.
| Macro | Description | Valeur par défaut | Obligatoire |
|---|---|---|---|
| KUBERNETESAPIHOSTNAME | Hostname or address of the Kubernetes API service | X | |
| KUBERNETESAPITOKEN | Token retrieved from service account | X | |
| KUBERNETESAPIPROTO | Specify https if needed | https | |
| KUBERNETESAPIPORT | API port | 443 | |
| KUBERNETESAPICUSTOMMODE | When a plugin offers several ways (CLI, library, etc.) to get information the desired one must be defined with this option | api | |
| KUBERNETESAPINAMESPACE | Set namespace to get informations | ||
| KUBERNETESNODENAME | Filter StatefulSet name (can be a regexp) | ||
| PROXYURL | Proxy URL if any | ||
| TIMEOUT | Set timeout in seconds | 10 | |
| EXTRAOPTIONS | Any extra option you may want to add to every command (a --verbose flag for example). Toutes les options sont listées ici. |
- Déployez la configuration. L'hôte apparaît dans la liste des hôtes supervisés, et dans la page Statut des ressources. La commande envoyée par le connecteur est indiquée dans le panneau de détails de l'hôte : celle-ci montre les valeurs des macros.
Pour la découverte d'hôte : définissez le jeton récupéré plus tôt à partir du compte de service,
- Ajoutez un hôte à Centreon depuis la page Configuration > Hôtes.
- Complétez les champs Nom, Alias & IP Address/DNS correspondant à votre ressource.
- Appliquez le modèle d'hôte Cloud-Kubernetes-Node-Kubectl-custom. Une liste de macros apparaît. Les macros vous permettent de définir comment le connecteur se connectera à la ressource, ainsi que de personnaliser le comportement du connecteur.
- Renseignez les macros désirées. Attention, certaines macros sont obligatoires, notamment la macro permettant de définir le custom mode, c'est-à-dire la méthode de connexion à la ressource.
| Macro | Description | Valeur par défaut | Obligatoire |
|---|---|---|---|
| KUBECTLCONFIGFILE | Kubernetes configuration file path. | ~/.kube/config | X |
| KUBERNETESAPICUSTOMMODE | When a plugin offers several ways (CLI, library, etc.) to get information the desired one must be defined with this option | kubectl | |
| KUBERNETESNODENAME | Filter StatefulSet name (can be a regexp) | ||
| PROXYURL | Proxy URL if any | ||
| TIMEOUT | Set timeout in seconds | 10 | |
| EXTRAOPTIONS | Any extra option you may want to add to every command (a --verbose flag for example). Toutes les options sont listées ici. |
- Déployez la configuration. L'hôte apparaît dans la liste des hôtes supervisés, et dans la page Statut des ressources. La commande envoyée par le connecteur est indiquée dans le panneau de détails de l'hôte : celle-ci montre les valeurs des macros.
Pour la découverte d'hôte : définissez le chemin vers le fichier de configuration créé (utilisez le chemin relatif pour le faire fonctionner à la fois pour la découverte et la supervision, c'est-à-dire
~/.kube/config).
Utiliser un modèle de service issu du connecteur
- Si vous avez utilisé un modèle d'hôte et coché la case Créer aussi les services liés aux modèles, les services associés au modèle ont été créés automatiquement, avec les modèles de services correspondants. Sinon, créez les services désirés manuellement et appliquez-leur un modèle de service.
- Renseignez les macros désirées (par exemple, ajustez les seuils d'alerte). Les macros indiquées ci-dessous comme requises (Obligatoire) doivent être renseignées.
- Cluster-Events
- CronJob-Status
- Daemonset-Status
- Deployment-Status
- Node-Status
- Node-Usage
- PersistentVolume-Status
- Pod-Status
- ReplicaSet-Status
- ReplicationController-Status
- StatefulSet-Status
| Macro | Description | Valeur par défaut | Obligatoire |
|---|---|---|---|
| FILTERTYPE | Filter event type (can be a regexp) | .* | |
| FILTERNAMESPACE | Filter namespace (can be a regexp) | .* | |
| WARNINGSTATUS | Define the conditions to match for the status to be WARNING (default: '%{type} =~ /warning/i') Can use special variables like: %{name}, %{namespace}, %{type}, %{object}, %{message}, %{count}, %{first_seen}, %{last_seen} | %{type} =~ /warning/i | |
| CRITICALSTATUS | Define the conditions to match for the status to be CRITICAL (default: '%{type} =~ /error/i'). Can use special variables like: %{name}, %{namespace}, %{type}, %{object}, %{message}, %{count}, %{first_seen}, %{last_seen} | %{type} =~ /error/i | |
| EXTRAOPTIONS | Any extra option you may want to add to the command (a --verbose flag for example). Toutes les options sont listées ici. | --verbose |
| Macro | Description | Valeur par défaut | Obligatoire |
|---|---|---|---|
| FILTERCRONJOB | Filter CronJob name (can be a regexp) | .* | |
| FILTERNAMESPACE | Filter CronJob namespace (can be a regexp) | .* | |
| WARNINGSTATUS | Define the conditions to match for the status to be WARNING (default: '') You can use the following variables: %{name}, %{namespace}, %{active}, %{last_schedule} | ||
| CRITICALSTATUS | Define the conditions to match for the status to be CRITICAL (default: ''). You can use the following variables: %{name}, %{namespace}, %{active}, %{last_schedule} | ||
| EXTRAOPTIONS | Any extra option you may want to add to the command (a --verbose flag for example). Toutes les options sont listées ici. | --verbose |
| Macro | Description | Valeur par défaut | Obligatoire |
|---|---|---|---|
| FILTERDAEMONSET | Filter DaemonSet name (can be a regexp) | .* | |
| FILTERNAMESPACE | Filter DaemonSet namespace (can be a regexp) | .* | |
| WARNINGSTATUS | Define the conditions to match for the status to be WARNING (default: '%{up_to_date}< %{desired}') You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{available}, %{unavailable}, %{up_to_date}, %{ready}, %{misscheduled} | %{up_to_date}< %{desired} | |
| CRITICALSTATUS | Define the conditions to match for the status to be CRITICAL (default: '%{available} < %{desired}'). You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{available}, %{unavailable}, %{up_to_date}, %{ready}, %{misscheduled} | %{available} < %{desired} | |
| EXTRAOPTIONS | Any extra option you may want to add to the command (a --verbose flag for example). Toutes les options sont listées ici. | --verbose |
| Macro | Description | Valeur par défaut | Obligatoire |
|---|---|---|---|
| FILTERDEPLOYMENT | Filter deployment name (can be a regexp) | .* | |
| FILTERNAMESPACE | Filter deployment namespace (can be a regexp) | .* | |
| WARNINGSTATUS | Define the conditions to match for the status to be WARNING (default: '%{up_to_date}< %{desired}') You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{available}, %{unavailable}, %{up_to_date} | %{up_to_date}< %{desired} | |
| CRITICALSTATUS | Define the conditions to match for the status to be CRITICAL (default: '%{available} < %{desired}'). You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{available}, %{unavailable}, %{up_to_date} | %{available} < %{desired} | |
| EXTRAOPTIONS | Any extra option you may want to add to the command (a --verbose flag for example). Toutes les options sont listées ici. | --verbose |
| Macro | Description | Valeur par défaut | Obligatoire |
|---|---|---|---|
| CRITICALSTATUS | Define the conditions to match for the status to be CRITICAL (default: '(%{type} =~ /Ready/i && %{status} !~ /True/i) || (%{type} =~ /.*Pressure/i && %{status} !~ /False/i)'). You can use the following variables: %{type}, %{status}, %{reason}, %{message}, %{name} | (%{type} =~ /Ready/i && %{status} !~ /True/i) || (%{type} =~ /.*Pressure/i && %{status} !~ /False/i) | |
| WARNINGSTATUS | Define the conditions to match for the status to be WARNING (default: ''). You can use the following variables: %{type}, %{status}, %{reason}, %{message}, %{name} | ||
| EXTRAOPTIONS | Any extra option you may want to add to the command (a --verbose flag for example). Toutes les options sont listées ici. | --verbose |
| Macro | Description | Valeur par défaut | Obligatoire |
|---|---|---|---|
| WARNINGALLOCATEDPODS | Thresholds (in percentage) | ||
| CRITICALALLOCATEDPODS | Thresholds (in percentage) | ||
| WARNINGCPULIMITS | Thresholds (in percentage) | ||
| CRITICALCPULIMITS | Thresholds (in percentage) | ||
| WARNINGCPUREQUESTS | Thresholds (in percentage) | ||
| CRITICALCPUREQUESTS | Thresholds (in percentage) | ||
| WARNINGMEMORYLIMITS | Thresholds (in percentage) | ||
| CRITICALMEMORYLIMITS | Thresholds (in percentage) | ||
| WARNINGMEMORYREQUESTS | Thresholds (in percentage) | ||
| CRITICALMEMORYREQUESTS | Thresholds (in percentage) | ||
| EXTRAOPTIONS | Any extra option you may want to add to the command (a --verbose flag for example). Toutes les options sont listées ici. | --verbose |
| Macro | Description | Valeur par défaut | Obligatoire |
|---|---|---|---|
| FILTERPERSISTENTVOLUME | Filter persistent volume name (can be a regexp) | .* | |
| FILTERNAMESPACE | Filter persistent volume name (can be a regexp). | .* | |
| CRITICALSTATUS | Define the conditions to match for the status to be CRITICAL (default: '%{phase} !~ /Bound|Available|Released/i'). You can use the following variables: %{name}, %{phase} | %{phase} !~ /Bound|Available|Released/i | |
| WARNINGSTATUS | Define the conditions to match for the status to be WARNING (default: '') You can use the following variables: %{name}, %{phase} | ||
| EXTRAOPTIONS | Any extra option you may want to add to the command (a --verbose flag for example). Toutes les options sont listées ici. | --verbose |
| Macro | Description | Valeur par défaut | Obligatoire |
|---|---|---|---|
| FILTERPOD | Filter pod name (can be a regexp) | .* | |
| FILTERNAMESPACE | Filter pod namespace (can be a regexp) | .* | |
| UNITS | Units of thresholds (default: '%') ('%', 'count') | % | |
| WARNINGCONTAINERSREADY | Warning threshold | ||
| CRITICALCONTAINERSREADY | Critical threshold | ||
| CRITICALCONTAINERSTATUS | Define the conditions to match for the status to be CRITICAL (default: '%{status} !~ /running/i || %{state} !~ /^ready$/'). You can use the following variables: %{status}, %{state}, %{name} | %{status} !~ /running/i || %{state} !~ /^ready$/ | |
| WARNINGCONTAINERSTATUS | Define the conditions to match for the status to be WARNING (default: ''). You can use the following variables: %{status}, %{name} | ||
| CRITICALPODSTATUS | Define the conditions to match for the status to be CRITICAL (default: '%{status} !~ /running/i'). You can use the following variables: %{status}, %{name}, %{namespace} | %{status} !~ /running/i | |
| WARNINGPODSTATUS | Define the conditions to match for the status to be WARNING (default: ''). You can use the following variables: %{status}, %{name}, %{namespace} | ||
| WARNINGRESTARTSCOUNT | Warning threshold | ||
| CRITICALRESTARTSCOUNT | Critical threshold | ||
| WARNINGTOTALRESTARTSCOUNT | Warning threshold | ||
| CRITICALTOTALRESTARTSCOUNT | Critical threshold | ||
| EXTRAOPTIONS | Any extra option you may want to add to the command (a --verbose flag for example). Toutes les options sont listées ici. | --verbose |
| Macro | Description | Valeur par défaut | Obligatoire |
|---|---|---|---|
| FILTERREPLICATSET | Filter ReplicaSet name (can be a regexp) | .* | |
| FILTERNAMESPACE | Filter ReplicaSet namespace (can be a regexp) | .* | |
| CRITICALSTATUS | Define the conditions to match for the status to be CRITICAL (default: '%{ready} < %{desired}'). You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{ready} | %{ready} < %{desired} | |
| WARNINGSTATUS | Define the conditions to match for the status to be WARNING (default: '') You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{ready} | ||
| EXTRAOPTIONS | Any extra option you may want to add to the command (a --verbose flag for example). Toutes les options sont listées ici. | --verbose |
| Macro | Description | Valeur par défaut | Obligatoire |
|---|---|---|---|
| FILTERREPLICATIONCONTROLLER | Filter ReplicationController name (can be a regexp) | .* | |
| FILTERNAMESPACE | Filter ReplicationController namespace (can be a regexp) | .* | |
| CRITICALSTATUS | Define the conditions to match for the status to be CRITICAL (default: '%{ready} < %{desired}'). You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{ready} | %{ready} < %{desired} | |
| WARNINGSTATUS | Define the conditions to match for the status to be WARNING (default: '') You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{ready} | ||
| EXTRAOPTIONS | Any extra option you may want to add to the command (a --verbose flag for example). Toutes les options sont listées ici. | --verbose |
| Macro | Description | Valeur par défaut | Obligatoire |
|---|---|---|---|
| FILTERSTATEFULSET | Filter StatefulSet name (can be a regexp) | .* | |
| FILTERNAMESPACE | Filter StatefulSet namespace (can be a regexp) | .* | |
| WARNINGSTATUS | Define the conditions to match for the status to be WARNING (default: '%{up_to_date}< %{desired}') You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{up_to_date}, %{ready} | %{up_to_date}< %{desired} | |
| CRITICALSTATUS | Define the conditions to match for the status to be CRITICAL (default: '%{ready} < %{desired}'). You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{up_to_date}, %{ready} | %{ready} < %{desired} | |
| EXTRAOPTIONS | Any extra option you may want to add to the command (a --verbose flag for example). Toutes les options sont listées ici. | --verbose |
- Déployez la configuration. Le service apparaît dans la liste des services supervisés, et dans la page Statut des ressources. La commande envoyée par le connecteur est indiquée dans le panneau de détails du service : celle-ci montre les valeurs des macros.
Comment puis-je tester le plugin et que signifient les options des commandes ?
Une fois le plugin installé, vous pouvez tester celui-ci directement en ligne
de commande depuis votre collecteur Centreon en vous connectant avec
l'utilisateur centreon-engine (su - centreon-engine). Vous pouvez tester
que le connecteur arrive bien à superviser une ressource en utilisant une commande
telle que celle-ci (remplacez les valeurs d'exemple par les vôtres) :
/usr/lib/centreon/plugins/centreon_kubernetes_api.pl \
--plugin=cloud::kubernetes::plugin \
--mode=statefulset-status \
--custommode='api' \
--hostname= \
--port='443' \
--proto='https' \
--token='' \
--config-file='' \
--proxyurl='' \
--namespace='' \
--timeout='10' \
--filter-name='.*' \
--filter-namespace='.*' \
--warning-status='%\{up_to_date\} < %\{desired\}' \
--critical-status='%\{ready\} < %\{desired\}' \
--verbose
La commande devrait retourner un message de sortie similaire à :
OK: All StatefulSets status are ok |
Diagnostic des erreurs communes
Voici quelques erreurs courantes et leur description. Vous devrez souvent
utiliser l'option --debug pour obtenir l'erreur exacte.
| Erreur | Description |
|---|---|
UNKNOWN: Cannot decode json response: Can't connect to <hostname>:<port> (certificate verify failed) | This error may appear if the TLS certificate is self-signed. Use the option --ssl-opt="SSL_verify_mode => SSL_VERIFY_NONE" to omit the certificate validity. |
UNKNOWN: API return error code '401' (add --debug option for detailed message) | If adding --debug option, API response message says Unauthorized. It generally means that the provided token is not valid. |
UNKNOWN: API return error code '403' (add --debug option for detailed message) | If adding --debug option, API response message says nodes is forbidden: User "system:serviceaccount:<namespace>:<account>" cannot list resource "nodes" in API group "" at the cluster scope. It means that the cluster role RBAC bound to the service account does not have the necessary privileges |
UNKNOWN: CLI return error code '1' (add --debug option for detailed message) | If adding --debug option, CLI response message says error: stat ~/.kube/config:: no such file or directory. The provided configuration file cannot be found. |
UNKNOWN: CLI return error code '1' (add --debug option for detailed message) | If adding --debug option, CLI response message says error: error loading config file "/root/.kube/config": open /root/.kube/config: permission denied. The provided configuration file cannot be read by current user. |
UNKNOWN: CLI return error code '1' (add --debug option for detailed message) | If adding --debug option, CLI response message says error: error loading config file "/root/.kube/config": v1.Config.AuthInfos: []v1.NamedAuthInfo: v1.NamedAuthInfo.AuthInfo: v1.AuthInfo.ClientKeyData: decode base64: illegal base64.... The provided configuration file is not valid. |
UNKNOWN: CLI return error code '1' (add --debug option for detailed message) | If adding --debug option, CLI response message says The connection to the server <hostname>:<port> was refused - did you specify the right host or port?. The provided configuration file is not valid. |
Pour plus d'informations, rendez-vous sur la documentation dédiée des plugins basés sur HTTP/API.
Modes disponibles
Dans la plupart des cas, un mode correspond à un modèle de service. Le mode est renseigné dans la commande d'exécution du connecteur. Dans l'interface de Centreon, il n'est pas nécessaire de les spécifier explicitement, leur utilisation est implicite dès lors que vous utilisez un modèle de service. En revanche, vous devrez spécifier le mode correspondant à ce modèle si vous voulez tester la commande d'exécution du connecteur dans votre terminal.
Tous les modes disponibles peuvent être affichés en ajoutant le paramètre
--list-mode à la commande :
/usr/lib/centreon/plugins/centreon_kubernetes_api.pl \
--plugin=cloud::kubernetes::plugin \
--list-mode
Le plugin apporte les modes suivants :
| Mode | Modèle de service associé |
|---|---|
| cluster-events [code] | Cloud-Kubernetes-Cluster-Events-Api-custom |
| cronjob-status [code] | Cloud-Kubernetes-CronJob-Status-Api-custom |
| daemonset-status [code] | Cloud-Kubernetes-Daemonset-Status-Api-custom |
| deployment-status [code] | Cloud-Kubernetes-Deployment-Status-Api-custom |
| discovery [code] | Used for host discovery |
| list-cronjobs [code] | Used for service discovery |
| list-daemonsets [code] | Used for service discovery |
| list-deployments [code] | Used for service discovery |
| list-ingresses [code] | Not used in this Monitoring Connector |
| list-namespaces [code] | Not used in this Monitoring Connector |
| list-nodes [code] | Used for service discovery |
| list-persistentvolumes [code] | Used for service discovery |
| list-pods [code] | Used for service discovery |
| list-replicasets [code] | Used for service discovery |
| list-replicationcontrollers [code] | Used for service discovery |
| list-services [code] | Not used in this Monitoring Connector |
| list-statefulsets [code] | Used for service discovery |
| node-status [code] | Cloud-Kubernetes-Node-Status-Api-custom Cloud-Kubernetes-Node-Status-Name-Api-custom |
| node-usage [code] | Cloud-Kubernetes-Node-Usage-Api-custom Cloud-Kubernetes-Node-Usage-Name-Api-custom |
| persistentvolume-status [code] | Cloud-Kubernetes-PersistentVolume-Status-Api-custom |
| pod-status [code] | Cloud-Kubernetes-Pod-Status-Api-custom |
| replicaset-status [code] | Cloud-Kubernetes-ReplicaSet-Status-Api-custom |
| replicationcontroller-status [code] | Cloud-Kubernetes-ReplicationController-Status-Api-custom |
| statefulset-status [code] | Cloud-Kubernetes-StatefulSet-Status-Api-custom |
Custom modes disponibles
Ce connecteur offre plusieurs méthodes pour se connecter à la ressource (CLI, bibliothèque, etc.), appelées custom modes.
Tous les custom modes disponibles peuvent être affichés en ajoutant le paramètre
--list-custommode à la commande :
/usr/lib/centreon/plugins/centreon_kubernetes_api.pl \
--plugin=cloud::kubernetes::plugin \
--list-custommode
Le plugin apporte les custom modes suivants :
- api
- kubectl
Options disponibles
Options génériques
Les options génériques sont listées ci-dessous :
| Option | Description |
|---|---|
| --mode | Define the mode in which you want the plugin to be executed (see--list-mode). |
| --dyn-mode | Specify a mode with the module's path (advanced). |
| --list-mode | List all available modes. |
| --mode-version | Check minimal version of mode. If not, unknown error. |
| --version | Return the version of the plugin. |
| --custommode | When a plugin offers several ways (CLI, library, etc.) to get information the desired one must be defined with this option. |
| --list-custommode | List all available custom modes. |
| --multiple | Multiple custom mode objects. This may be required by some specific modes (advanced). |
| --pass-manager | Define the password manager you want to use. Supported managers are: environment, file, keepass, hashicorpvault and teampass. |
| --verbose | Display extended status information (long output). |
| --debug | Display debug messages. |
| --filter-perfdata | Filter perfdata that match the regexp. Example: adding --filter-perfdata='avg' will remove all metrics that do not contain 'avg' from performance data. |
| --filter-perfdata-adv | Filter perfdata based on a "if" condition using the following variables: label, value, unit, warning, critical, min, max. Variables must be written either %{variable} or %(variable). Example: adding --filter-perfdata-adv='not (%(value) == 0 and %(max) eq "")' will remove all metrics whose value equals 0 and that don't have a maximum value. |
| --explode-perfdata-max | Create a new metric for each metric that comes with a maximum limit. The new metric will be named identically with a '_max' suffix). Example: it will split 'used_prct'=26.93%;0:80;0:90;0;100 into 'used_prct'=26.93%;0:80;0:90;0;100 'used_prct_max'=100%;;;; |
| --change-perfdata --extend-perfdata | Change or extend perfdata. Syntax: --extend-perfdata=searchlabel,newlabel,target[,[newuom],[min],[m ax]] Common examples: Convert storage free perfdata into used: --change-perfdata='free,used,invert()' Convert storage free perfdata into used: --change-perfdata='used,free,invert()' Scale traffic values automatically: --change-perfdata='traffic,,scale(auto)' Scale traffic values in Mbps: --change-perfdata='traffic_in,,scale(Mbps),mbps' Change traffic values in percent: --change-perfdata='traffic_in,,percent()' |
| --extend-perfdata-group | Add new aggregated metrics (min, max, average or sum) for groups of metrics defined by a regex match on the metrics' names. Syntax: --extend-perfdata-group=regex,namesofnewmetrics,calculation[,[ne wuom],[min],[max]] regex: regular expression namesofnewmetrics: how the new metrics' names are composed (can use $1, $2... for groups defined by () in regex). calculation: how the values of the new metrics should be calculated newuom (optional): unit of measure for the new metrics min (optional): lowest value the metrics can reach max (optional): highest value the metrics can reach Common examples: Sum wrong packets from all interfaces (with interface need --units-errors=absolute): --extend-perfdata-group=',packets_wrong,sum(packets_(discard |error)_(in|out))' Sum traffic by interface: --extend-perfdata-group='traffic_in_(.*),traffic_$1,sum(traf fic_(in|out)_$1)' |
| --change-short-output --change-long-output | Modify the short/long output that is returned by the plugin. Syntax: --change-short-output=pattern |
| --change-exit | Replace an exit code with one of your choice. Example: adding --change-exit=unknown=critical will result in a CRITICAL state instead of an UNKNOWN state. |
| --range-perfdata | Rewrite the ranges displayed in the perfdata. Accepted values: 0: nothing is changed. 1: if the lower value of the range is equal to 0, it is removed. 2: remove the thresholds from the perfdata. |
| --filter-uom | Mask the units when they don't match the given regular expression. |
| --opt-exit | Replace the exit code in case of an execution error (i.e. wrong option provided, SSH connection refused, timeout, etc). Default: unknown. |
| --output-ignore-perfdata | Remove all the metrics from the service. The service will still have a status and an output. |
| --output-ignore-label | Remove the status label ("OK:", "WARNING:", "UNKNOWN:", CRITICAL:") from the beginning of the output. Example: 'OK: Ram Total:...' will become 'Ram Total:...' |
| --output-xml | Return the output in XML format (to send to an XML API). |
| --output-json | Return the output in JSON format (to send to a JSON API). |
| --output-openmetrics | Return the output in OpenMetrics format (to send to a tool expecting this format). |
| --output-file | Write output in file (can be combined with json, xml and openmetrics options). E.g.: --output-file=/tmp/output.txt will write the output in /tmp/output.txt. |
| --disco-format | Applies only to modes beginning with 'list-'. Returns the list of available macros to configure a service discovery rule (formatted in XML). |
| --disco-show | Applies only to modes beginning with 'list-'. Returns the list of discovered objects (formatted in XML) for service discovery. |
| --float-precision | Define the float precision for thresholds (default: 8). |
| --source-encoding | Define the character encoding of the response sent by the monitored resource Default: 'UTF-8'. Kubernetes CLI (kubectl) |
| --namespace | Set namespace to get informations. |
| --timeout | Set timeout in seconds (default: 10). |
| --proxyurl | Proxy URL if any |
Options des custom modes
Les options spécifiques aux custom modes sont listées ci-dessous :
- api
- kubectl
| Option | Description |
|---|---|
| --hostname | Kubernetes API hostname. |
| --port | API port (default: 443) |
| --proto | Specify https if needed (default: 'https') |
| --timeout | Set HTTP timeout (default: 10) |
| --limit | Number of responses to return for each list calls. See https://kubernetes.io/docs/reference/kubernetes-api/common-param eters/common-parameters/#limit (default: 100) |
| --namespace | Set namespace to get information. |
| --legacy-api-beta | If this option is set the legacy API path are set for this API calls: kubernetes_list_cronjobs will use this path: /apis/batch/v1beta1/namespaces/ and kubernetes_list_ingresses will use this path: /apis/extensions/v1beta1/namespaces/ . This ways are no longer served since K8S 1.22 see https://kubernetes.io/docs/reference/using-api/deprecation-guide/#ingress-v122 |
| --http-peer-addr | Set the address you want to connect to. Useful if hostname is only a vhost, to avoid IP resolution. |
| --proxyurl | Proxy URL. Example: http://my.proxy:3128 |
| --proxypac | Proxy pac file (can be a URL or a local file). |
| --insecure | Accept insecure SSL connections. |
| --http-backend | Perl library to use for HTTP transactions. Possible values are: lwp (default) and curl. |
| --ssl-opt | Set SSL Options (--ssl-opt="SSL_version => TLSv1" --ssl-opt="SSL_verify_mode => SSL_VERIFY_NONE"). |
| --curl-opt | Set CURL Options (--curl-opt="CURLOPT_SSL_VERIFYPEER => 0" --curl-opt="CURLOPT_SSLVERSION => CURL_SSLVERSION_TLSv1_1" ). |
| Option | Description |
|---|---|
| --config-file | Kubernetes configuration file path (default: '~/.kube/config'). (example: --config-file='/root/.kube/config'). |
| --context | Context to use in configuration file. |
| --namespace | Set namespace to get informations. |
| --timeout | Set timeout in seconds (default: 10). |
| --sudo | Use 'sudo' to execute the command. |
| --command | Command to get information (default: 'kubectl'). Can be changed if you have output in a file. |
| --command-path | Command path (default: none). |
| --command-options | Command options (default: none). |
| --proxyurl | Proxy URL if any |
Options des modes
Les options disponibles pour chaque modèle de services sont listées ci-dessous :
- Cluster-Events
- CronJob-Status
- Daemonset-Status
- Deployment-Status
- Node-Status*
- Node-Usage*
- PersistentVolume-Status
- Pod-Status
- ReplicaSet-Status
- ReplicationController-Status
- StatefulSet-Status
| Option | Description |
|---|---|
| --config-file | Kubernetes configuration file path (default: '~/.kube/config'). (example: --config-file='/root/.kube/config'). |
| --context | Context to use in configuration file. |
| --sudo | Use 'sudo' to execute the command. |
| --command | Command to get information (default: 'kubectl'). Can be changed if you have output in a file. |
| --command-path | Command path (default: none). |
| --command-options | Command options (default: none). |
| --filter-type | Filter event type (can be a regexp). |
| --filter-namespace | Filter namespace (can be a regexp). |
| --warning-status | Define the conditions to match for the status to be WARNING (default: '%{type} =~ /warning/i') Can use special variables like: %{name}, %{namespace}, %{type}, %{object}, %{message}, %{count}, %{first_seen}, %{last_seen}. |
| --critical-status | Define the conditions to match for the status to be CRITICAL (default: '%{type} =~ /error/i'). Can use special variables like: %{name}, %{namespace}, %{type}, %{object}, %{message}, %{count}, %{first_seen}, %{last_seen}. |
| Option | Description |
|---|---|
| --filter-name | Filter CronJob name (can be a regexp). |
| --filter-namespace | Filter CronJob namespace (can be a regexp). |
| --warning-status | Define the conditions to match for the status to be WARNING (default: '') You can use the following variables: %{name}, %{namespace}, %{active}, %{last_schedule}. |
| --critical-status | Define the conditions to match for the status to be CRITICAL (default: ''). You can use the following variables: %{name}, %{namespace}, %{active}, %{last_schedule}. |
| Option | Description |
|---|---|
| --filter-name | Filter DaemonSet name (can be a regexp). |
| --filter-namespace | Filter DaemonSet namespace (can be a regexp). |
| --warning-status | Define the conditions to match for the status to be WARNING (default: '%{up_to_date}< %{desired}') You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{available}, %{unavailable}, %{up_to_date}, %{ready}, %{misscheduled}. |
| --critical-status | Define the conditions to match for the status to be CRITICAL (default: '%{available} < %{desired}'). You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{available}, %{unavailable}, %{up_to_date}, %{ready}, %{misscheduled}. |
| Option | Description |
|---|---|
| --filter-name | Filter deployment name (can be a regexp). |
| --filter-namespace | Filter deployment namespace (can be a regexp). |
| --warning-status | Define the conditions to match for the status to be WARNING (default: '%{up_to_date}< %{desired}') You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{available}, %{unavailable}, %{up_to_date}. |
| --critical-status | Define the conditions to match for the status to be CRITICAL (default: '%{available} < %{desired}'). You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{available}, %{unavailable}, %{up_to_date}. |
| Option | Description |
|---|---|
| --filter-name | Filter node name (can be a regexp). |
| --warning-status | Define the conditions to match for the status to be WARNING (default: ''). You can use the following variables: %{type}, %{status}, %{reason}, %{message}, %{name}. |
| --critical-status | Define the conditions to match for the status to be CRITICAL (default: '(%{type} =~ /Ready/i && %{status} !~ /True/i) || (%{type} =~ /.*Pressure/i && %{status} !~ /False/i)'). You can use the following variables: %{type}, %{status}, %{reason}, %{message}, %{name}. |
| Option | Description |
|---|---|
| --filter-name | Filter node name (can be a regexp). |
| --warning-* --critical-* | Thresholds (in percentage). Can be: 'cpu-requests', 'cpu-limits', 'memory-requests', 'memory-limits', 'allocated-pods'. |
| Option | Description |
|---|---|
| --filter-name | Filter persistent volume name (can be a regexp). |
| --warning-status | Define the conditions to match for the status to be WARNING (default: '') You can use the following variables: %{name}, %{phase}. |
| --critical-status | Define the conditions to match for the status to be CRITICAL (default: '%{phase} !~ /Bound|Available|Released/i'). You can use the following variables: %{name}, %{phase}. |
| Option | Description |
|---|---|
| --filter-name | Filter pod name (can be a regexp). |
| --filter-namespace | Filter pod namespace (can be a regexp). |
| --extra-filter | Add an extra filter based on labels (can be defined multiple times) Example : --extra-filter='app=mynewapp' |
| --warning-pod-status | Define the conditions to match for the status to be WARNING (default: ''). You can use the following variables: %{status}, %{name}, %{namespace}. |
| --critical-pod-status | Define the conditions to match for the status to be CRITICAL (default: '%{status} !~ /running/i'). You can use the following variables: %{status}, %{name}, %{namespace}. |
| --warning-container-status | Define the conditions to match for the status to be WARNING (default: ''). You can use the following variables: %{status}, %{name}. |
| --critical-container-status | Define the conditions to match for the status to be CRITICAL (default: '%{status} !~ /running/i || %{state} !~ /^ready$/'). You can use the following variables: %{status}, %{state}, %{name}. |
| --warning-* | Warning threshold. Can be: 'containers-ready', 'total-restarts-count' (count), 'restarts-count' (count). |
| --critical-* | Critical threshold. Can be: 'containers-ready', 'total-restarts-count' (count), 'restarts-count' (count). |
| --units | Units of thresholds (default: '%') ('%', 'count'). |
| Option | Description |
|---|---|
| --filter-name | Filter ReplicaSet name (can be a regexp). |
| --filter-namespace | Filter ReplicaSet namespace (can be a regexp). |
| --warning-status | Define the conditions to match for the status to be WARNING (default: '') You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{ready}. |
| --critical-status | Define the conditions to match for the status to be CRITICAL (default: '%{ready} < %{desired}'). You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{ready}. |
| Option | Description |
|---|---|
| --filter-name | Filter ReplicationController name (can be a regexp). |
| --filter-namespace | Filter ReplicationController namespace (can be a regexp). |
| --warning-status | Define the conditions to match for the status to be WARNING (default: '') You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{ready}. |
| --critical-status | Define the conditions to match for the status to be CRITICAL (default: '%{ready} < %{desired}'). You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{ready}. |
| Option | Description |
|---|---|
| --filter-name | Filter StatefulSet name (can be a regexp). |
| --filter-namespace | Filter StatefulSet namespace (can be a regexp). |
| --warning-status | Define the conditions to match for the status to be WARNING (default: '%{up_to_date}< %{desired}') You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{up_to_date}, %{ready}. |
| --critical-status | Define the conditions to match for the status to be CRITICAL (default: '%{ready} < %{desired}'). You can use the following variables: %{name}, %{namespace}, %{desired}, %{current}, %{up_to_date}, %{ready}. |
Pour un mode, la liste de toutes les options disponibles et leur signification peut être
affichée en ajoutant le paramètre --help à la commande :
/usr/lib/centreon/plugins/centreon_kubernetes_api.pl \
--plugin=cloud::kubernetes::plugin \
--mode=statefulset-status \
--custommode='api' \
--help